發布日期:2022-07-14 點擊率:42
延伸到40kHz的音頻頻譜被劃分為兩個頻段。語音分量占用頻譜的較低部分,從5Hz到7kHz,其他音頻分量占余下的高頻部分,如圖1所示。
語音處理主要涉及壓縮-解壓縮、識別、調整和增強算法。信號處理算法非常依賴于系統資源,例如可用的存儲器和時鐘性能。由于這些資源會增加系統的成本,因此產品提供商通常都限制這些資源,以降低產品成本。一些基本特性,例如存儲器和時鐘消耗是算法復雜性的必然部分。復雜性越低,算法越優,其實現的功效就越高。
在評估一個算法時,測量算法的復雜性是第一步。在特定處理器上運行算法所要求的時鐘決定了處理能力,它取決于架構,不同的處理器架構其處理能力是有變化的。而算法的存儲器需求明顯不會改變。絕大多數的DSP算法對一組樣值進行處理,這樣的一組樣值稱為一個幀。一組樣值組成一個幀將不可避免引入延遲,并產生處理延遲。國際電聯(ITU)規定了每種算法的可接受延遲標準。
算法的處理能力通常用“每秒百萬時鐘”來表示,或者MCPS。為了更好地理解MCPS,可以假設某個算法以8kHz的頻率處理64個采樣幀,處理每個幀需要300,000個時鐘。那么收集一個幀的時間為64/8,000或8ms。通過簡單的算法可以得出每秒可以處理125個幀。當算法處理所有的幀,它至少占用內核每秒300,000*125 = 37,500,000個時鐘,或者。
另外一種表達MCPS的方式是,它等于(處理一個幀所要求的時間乘以采樣頻率再除以幀大小)再除以1百萬。
通常用來定義算法處理能力的第二個術語是MIPS,或百萬指令每秒。計算某個算法的MIPS也比較復雜。如果處理器每個時鐘周期能有效地執行一個指令,每個處理器的MIPS和MCPS是相同的。另一方面,如果處理器的架構需要超過一個周期來執行一個指令,則MCPS和MIPS之間存在一個比例。例如,一個ARM7TDMI處理器實際上每個指令需要1.1個周期。
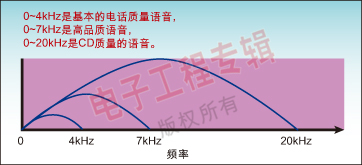
圖1:音頻頻譜圖。
在進行集成之前
在任何嵌入式系統上開始集成和評估任何語音算法的最佳時機是當系統處于一個可預測或穩定的狀態時。‘穩定’意味著音頻前端的中斷結構是一致的。換言之,當保持一個合適的幅值時,甚至不會丟失一個數據字節。擁有可用系統存儲器和時鐘的統計數據是非常明智的。在一個工作穩定的現有系統上集成一個算法相對較簡單。如果系統正在開發中,試圖在這個系統上集成和評估任何算法之前需要徹底對音頻前端進行測試。而且,要驗證在系統內沒有中斷發生相互沖突。如果系統中存在任何問題,算法的調試將是非常痛苦的體驗。
在將要集成音頻/語音算法的系統中,音頻固件必須是穩健的,它必須為算法提供準確的數據才能使算法得以有效地執行。工程師常常犯的一個簡單錯誤是在每個樣值到來時中斷內核。如果算法只是對一個幀的某些固定樣值進行處理,那么其他的中斷將是多余的。可以通過配置直接存儲器存取(DMA)和內部FIFO來在整個幀收集完成后再中斷內核。
實例算法
當開發任何電信系統時,工程師通常用脈碼調制(PCM)編解碼器(即標準)進行語音質量的測試。這種窄帶編解碼器將樣值幅度限制在8bit的精度,并產生64kbit/s的吞吐量。編碼器和解碼器可能會對每個數據樣值進行處理。它是一種非權重算法,復雜度很低,幾乎沒有處理延遲,工程師可以選擇利用編解碼器來進行播放、驗證系統,更重要的是徹底評估音頻前端設計。工程師可以檢測信號電平,調整硬件編解碼器增益,同步近端和遠端中斷,驗證DMA功能,以及使用這種基本的電話標準成功進行其他試驗。在這個過程中,如果發現從另一端接收到的壓縮數據是比特反序的,請不要覺得奇怪。一段反序代碼就能解決這個問題。
任何寬帶語音編解碼器都是較多占用存儲器和時鐘資源的語音算法的一個實例。子帶ADPCM(自適應差分脈碼調制)算法就是其中之一,相應標準是 。它對16kHz采樣的數據進行處理,因此覆蓋了整個語音頻譜。它保留了未發聲的頻率分量—那些存在于4到7kHz的分量—從而提供了高質量的自然語音。在任何編解碼器集成到系統之前,強烈建議認真測試。盡管編碼和解碼可以逐個樣值進行測試,但涉及到濾波和其他頻域算法的編解碼器測試是完全不同的,它需要采用至少有數千個樣值的數據流。編解碼器的驗證讓工程師忙于利用ITU向量進行單元測試、信號電平測試以及與其他可用編解碼器的可互操作測試。對于系統集成工程師來說,與在發送之前將編碼后的數據字節編成16比特的字以及信號電平的失配相關的互操作問題都不是新的問題。
這里討論的算法未必是系統工程師可能會集成的算法,因為這些算法需要更多的系統存儲器和時鐘周期。處理器增強型算法的其他實例包括回聲消除算法、噪聲抑制算法以及維特比算法。對這些算法的性能評估并不像語音編解碼器那樣簡單。
通常,任何涉及到免提或揚聲器模式的電信系統都采用了聲學回波消除算法來避免聽到自己的回聲。如果在嘈雜的環境中采用,還需要采用噪聲控制算法。回聲消除-噪聲抑制(ECNR)需要大量的系統存儲器和時鐘。有多種時域與頻域技術可用來減輕聲學回聲問題,如表1所示。

表1:前面四行表明頻域技術優于時域技術,后面四行支持時域技術。
事實證明頻域方法更有效,因為它的運算成本較低。這種方法采用自適應FIR濾波器,它只在當殘余回聲誤差大于門限值時才更新其系數。從輸入信號中減去估計的回聲將產生誤差。來自第二方的信號被用作這些算法的基準來估計回聲。需要為算法提供適當的基準才能取得良好的回聲估計和消除。
另外一個因素是回聲尾部長度,它是以毫秒為單位的回聲反射時間。簡單而言,它是回聲形成的時間。該因素取決于環境的維度。盡管詳細的濾波器設計是一個很復雜的話題,但選擇濾波器的長度并不太復雜(見表2):
濾波器長度= 回聲尾長×采樣頻率

表2:說明了數據以8kHz采樣時尾部長度與回波覆蓋距離以及濾波器長度要求之間的關系。
任何回波消除(EC)實現的基本要求是支持最低16kHz的采樣數據,以確保能涵蓋16kHz的寬帶語音。將EC與寬帶語音編解碼器集成需要更加小心,因為回波尾長取決于采樣頻率,采樣率為8kHz的數據需要72ms的EC才能有效地消除回聲,當用于16kHz采樣數據時,只能消除一半。因此,工程師發現將半有效的EC與寬帶編解碼器集成是一個雙倍挑戰的工作。噪聲消除方法也已經使用了多年。針對不同的應用,方法的選擇、實現和應用也不同。例如,某種方法可能將噪聲視為比人聲更加固定。算法將建立噪聲模型,然后從輸入信號中減去噪聲。噪聲降低的大小按分貝來度量。對于很多應用來說10到30dB的衰減就很不錯。
本文所述應用中的EC尾長要求大約為50ms,要求的噪聲抑制水平在12到25dB之間,具體取決于噪聲屬性以及期望的輸出語音質量。通常,噪聲消除越多,越有可能損失語音質量。因此,動態選擇大小將能提供一個合適的噪聲消減量,同時依然保持足夠的語音質量。對于這種應用的ECNR組合可能需要高達15到20kB的系統存儲器。每個64采樣幀的處理可能耗用150,000到300,000個時鐘,具體數據取決于處理器。
ECNR組合的性能評估可能非常麻煩。通常可以通過調節硬件編解碼器的增益,調整麥克風和揚聲器的位置,發現遠端和近端語音和中斷的同步,發現具有線性屬性的音頻硬件,試驗不同的EC尾長和NR電平來獲得最佳可能的回聲消除和噪聲抑制性能。
在評估任何算法的復雜性的同時,初學者需要考慮最糟糕的情況,這很重要。算法的執行時間對于不同的幀來說可能不同。這種數據依賴性源于這樣一個事實,即一個處理器相乘兩個具有較高幅值樣值所需的時間要比相乘兩個幅值較低樣值的時間長。
可能受自適應算法誤導的一個實例是,當濾波系數未被更新時,所占用的周期將較少。濾波器數據的適配可能需要數千個時鐘周期,因此很明顯在分析MCPS測試時,需要考慮這一點。然而,不要僅僅依賴于算法,要嘗試不同的向量來發現最準確的MCPS和性能度量。
數據位和數據片的收集
本文討論的算法足以實現基本的電話系統。當系統具有一個以上增強算法時,需要調用的算法序列會有些不同。一些語音算法,例如噪聲消除算法,可能給其輸出帶來非線性屬性,這會降低其他算法的性能。這樣的算法必須放在語音增強處理過程的最后執行。
作者:Nitin Jain
MindTree公司